4. Data Manipulation¶
The following section will provide you with an understanding on how to manipulate modeled data
with fuddly primitives. Data manipulation is what disruptors perform (refer to Defining Specific Disruptors).
This chapter will enable you to write your own disruptors or to simply perform custom
manipulation of a data coming from a file, retrieved from the network (thanks to data
absorption—refer to Absorption of Raw Data that Complies to the Data Model), or even generated from scratch.
4.1. Overview¶
To guide you over what is possible to perform, let’s consider the following data model:
1 from framework.node import *
2 from framework.value_types import *
3 from framework.node_builder import *
4
5 example_desc = \
6 {'name': 'ex',
7 'contents': [
8 {'name': 'data0',
9 'contents': String(values=['Plip', 'Plop']) },
10
11 {'name': 'data_group',
12 'contents': [
13
14 {'name': 'len',
15 'mutable': False,
16 'contents': LEN(vt=UINT8, after_encoding=False),
17 'node_args': 'data1',
18 'absorb_csts': AbsFullCsts(contents=False)},
19
20 {'name': 'data1',
21 'contents': String(values=['Test!', 'Hello World!']) },
22
23 {'name': 'data2',
24 'qty': (1,3),
25 'semantics': ['sem1', 'sem2'],
26 'contents': UINT16_be(min=10, max=0xa0ff),
27 'alt': [
28 {'conf': 'alt1',
29 'contents': SINT8(values=[1,4,8])},
30 {'conf': 'alt2',
31 'contents': UINT16_be(min=0xeeee, max=0xff56)} ]},
32
33 {'name': 'data3',
34 'semantics': ['sem2'],
35 'sync_qty_with': 'data2',
36 'contents': UINT8(values=[30,40,50]),
37 'alt': [
38 {'conf': 'alt1',
39 'contents': SINT8(values=[1,4,8])}]},
40 ]},
41
42 {'name': 'data4',
43 'contents': String(values=['Red', 'Green', 'Blue']) }
44 ]}
This is what we call a data descriptor. It cannot be used directly, it should first be
transformed to fuddly internal representation based on framework.node.Node.
The code below shows how to perform that:
1 nb = NodeBuilder()
2 rnode = nb.create_graph_from_desc(example_desc)
3 rnode.set_env(Env())
fuddly models data as directed acyclic graphs whose terminal
nodes describe the different parts of a data format (refer to Data Modeling). In order to
enable elaborated manipulations it also creates a specific object to share between all the nodes
some common information related to the graph: the framework.node.Env object. You should
note that we create this environment object and setup the root node with it. Actually it
provides all the nodes of the graph with this environment. From now on it is possible to access
the environment from any node, and fuddly is now able to deal with this graph.
Note
The method framework.node_builder.NodeBuilder.create_graph_from_desc() return a
framework.node.Node which is the root of the graph.
Note
When you instantiate a modeled data from a model through
framework.data_model.DataModel.get_atom() as illustrated in Using fuddly Through Advanced Python Interpreter,
the environment object is created for you. Likewise, when you register a data descriptor through
framework.data_model.DataModel.register() (refer to Defining the Imaginary MyDF Data Model), no need to worry
about the environment.
Note
The framework.node_builder.NodeBuilder object which is used to create a
graph from a data descriptor is bound to the graph and should not be used for creating another
graph. It contains some information on the created graph such as a dictionary of all its
nodes mb.node_dico.
4.1.1. Generate Data a.k.a. Freeze a Graph¶
If you want to get a data from the graph you have to freeze it first as it represents many
different potential data at once (actually it acts like a template). To do so, just call the method
framework.node.Node.freeze() on the root node. It will provide you with a nested set of
lists containing the frozen value for each node selected within the graph to provide you with a data.
What is way more interesting in the general case is obtaining a byte string of the data. For
this you just have to call framework.node.Node.to_bytes() on the root node which will
first freeze the graph and then flatten the nested list automatically to provide you with
the byte string.
If you want to get another data from the graph you should first unfreeze it because otherwise any
further call to the previous methods will give you the same value. To do that you can call the
method framework.node.Node.unfreeze(). You will then be able to get a new data by
freezing it again. Actually doing so will produce the next data by cycling over the possible
node values (described in the graph) in a random or a determinist way (refer to Operations on Node Properties and Attributes).
If you look at getting data from the graph by walking over each of its nodes independently then
you should look for instance at the generic disruptor tWALK (refer to Generic Disruptors)
and also to the model walker infrastructure The Model Walker Infrastructure).
By default, unfreeze will act recursively and will affect every nodes reachable from the calling
one. You can unfreeze only the node on which the method is called by switching its recursive
parameter.
You may want to unfreeze the graph without changing its state, just because you performed some
modifications locally and want it to be taken into account when getting a new data from the graph.
(refer to Node Configurations for a usage example). For that purpose, you may use the
dont_change_state parameter of framework.node.Node.unfreeze() which allows
to unfreeze without cycling.
Another option you may want is to unfreeze only the constraints of your graph which based on
existence conditions (refer to How to Describe a Data Format Whose Parts Change Depending on Some Fields), generator and func nodes.
To do so, set the reevaluate_constraints parameter to True.
To cycle over the possible node values or shapes (for non terminal nodes) a state is kept.
This state is normally reset automatically when the node is exhausted in order to cycle again.
can be reset thanks to the method framework.node.Node.reset_state(). In
addition to resetting the node state it also unfreezes it.
Note
When a cycle over the possible node values or shapes is terminated, a notification is
raised (through the linked environment object). Depending on the Finite node attribute
generic disruptors will recycle the node or change to another one. Setting the Finite
property on all the graph will enable you to have an end on data generation, and to avoid
the generation of duplicated data.
Finally if you want to unfreeze all the node configurations (refer to Node Configurations) at
once, you should call the method framework.node.Node.unfreeze_all().
4.1.2. Create Nodes with Low-Level Primitives¶
Instead of using the high-level API for describing a graph you can create it by using fuddly
low-level primitives. Generally, you don’t need to go through that, but for specific
complex situations it could provide you with what you need. To create a graph or a single node,
you always have to instantiate the class framework.node.Node which enables you to set
the type of content for the main node configuration (refer to Node Configurations).
Depending on the content type the constructor will call the following methods to do the job:
framework.node.Node.set_values(): for typed-value nodes.framework.node.Node.set_subnodes_basic(): for non-terminal nodes without specifying a grammar.framework.node.Node.set_subnodes_with_csts(): for non-terminal nodes constrained by a grammar.framework.node.Node.set_generator_func(): for generator nodes.framework.node.Node.set_func(): for function nodes.
Note
Methods specific to the node content (framework.node.NodeInternals) can be
called directly on the node itself and it will be forwarded to the content (if the method name
does not match one the framework.node.Node class).
See also
If you want to learn more about the specific operations that can be performed on each kind of
content (whose base class is framework.node.NodeInternals), refer to the related
class, namely:
4.1.3. Cloning a Node¶
A graph or any node within can be cloned in order to be used anywhere else independently from the
original node. To perform such an operation you should use
framework.node.Node.get_clone() like in the following example:
1 rnode_copy = rnode.get_clone('mycopy')
rnode_copy is a clone of the root node of the previous graph example, and as such it is a
clone of the graph. The same operation can be achieved by creating a new node and passing as a
parameter the node to copy:
1 rnode_copy = Node('mycopy', base_node=rnode, new_env=True)
When you clone a node you may want to keep its current state or ignore it (that is, cloning
an unfrozen graph as if it was reset). For doing so, you have to use the parameter
ignore_frozen_state of the method framework.node.Node.get_clone(). By default it is
set to False which means that the state is preserved during the cloning process.
4.1.4. Display a Frozen Graph¶
If you want to display a frozen graph (representing one data) in ASCII-art you have to call the
method framework.node.Node.show() on it. For instance the following:
rnode.show()
will display a frozen graph that looks the same as the one below:
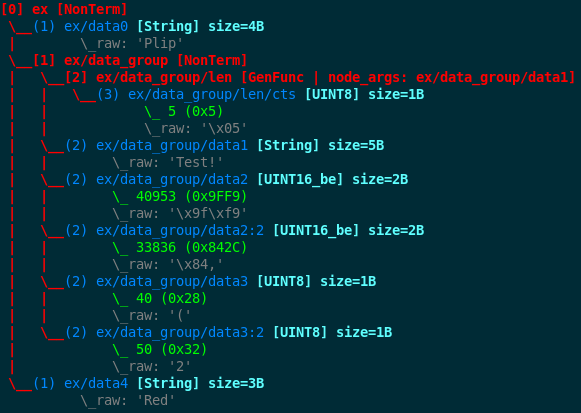
4.1.5. The Node Environment¶
The environment which should normally be the same for all the nodes of a same graph are handled by the following methods:
4.2. Search for Nodes in a Graph¶
Searching a graph for specific nodes can be performed in basically two ways. Depending on the criteria based on which you want to perform the search, you should use:
framework.node.Node.iter_nodes_by_path(): iterator that walk through all the nodes that match the graph path—you provide as a parameter—from the node on which the method is called (orNoneif nothing is found). The syntax defined to represent paths is similar to the one of filesystem paths. Each path are represented by a python string, where node names are separated by/’s. For instance the path from the root node of the previous data model to the node namedlenis:'ex/data_group/len'Note the path provided is interpreted as a regexp.
framework.node.Node.get_first_node_by_path(): use the previous iterator to provide the first node that match the graph path orNoneif nothing is foundframework.node.Node.get_reachable_nodes(): It is the more flexible primitive that enables to perform a search based on syntactic and/or semantic criteria. It can take several optional parameters to define your search like a graph path regexp. Unlike the previous method it always returns a list, either filled with the nodes that has been found or with nothing. You can use other kinds of criteria to be passed through the following parameters:internals_criteria: To be provided with aframework.node.NodeInternalsCriteriaobject. This object enable you to describe the syntactic properties you look for, such as:The node kind (refer to Operations on Node Properties and Attributes) and/or subkind (for a typed terminal node, a subkind is the class of its embedded typed value);
The node attributes (refer to Operations on Node Properties and Attributes)
The node constraints such as: existence or quantity synchronization. Usable constraints are defined by
framework.node.SyncScope.
semantics_criteria: To be provided with aframework.node.NodeSemanticCriteriaobject. This object enable you to describe the semantic properties you look for. They are currently limited to a list of python strings.owned_conf: The name of a node configuration (refer to Node Configurations) that the targeted nodes own.
Note
If the search is only path-based,
framework.node.Node.iter_nodes_by_path()is the preferable solution as it is more efficient.The following code snippet illustrates the use of such criteria for retrieving all the nodes coming from the
data2description (refer to Entangled Nodes):1from framework.plumbing import * 2from framework.node import * 3from framework.value_types import * 4 5fmk = FmkPlumbing() 6fmk.start() 7 8fmk.run_project(name='tuto') 9 10ex_node = fmk.dm.get_atom('ex') 11ex_node.freeze() 12 13ic = NodeInternalsCriteria(mandatory_attrs=[NodeInternals.Mutable], 14 node_kinds=[NodeInternals_TypedValue], 15 negative_node_subkinds=[String], 16 negative_csts=[SyncScope.Qty]) 17 18sc = NodeSemanticsCriteria(mandatory_criteria=['sem1', 'sem2']) 19 20ex_node.get_reachable_nodes(internals_criteria=ic, semantics_criteria=sc, 21 owned_conf='alt2')
Obviously, you don’t need all these criteria for retrieving such node. It’s only for exercise.
Note
For abstracting away the data model from the rest of the framework,
fuddlyuses the specific classframework.data.Datawhich acts as a data container. Thus, while interacting with the different part of the framework, Node-based data (or string-based data) should be encapsulated in aframework.data.Dataobject.For instance
Data(ex_node)will create an object that encapsulateex_node. Accessing the node again is done through the propertyframework.data.Data.content
4.3. The Node Dictionary Interface¶
The framework.node.Node implements the dictionary interface, which means the
following operation are possible on a node:
1node[key] # reading operation
2
3node[key] = value # writing operation
As a key, you can provide:
A path regexp (where the node on which the method is called is considered as the root) to the nodes you want to reach. A list of the nodes will be returned for the reading operation (or
Noneif the path match nothing), and for the writing operation all the matching nodes will get the new value. The reading operation is equivalent to callingframework.node.Node.iter_nodes_by_path()on the node and providing the parameterpath_regexpwith your path (except the method will return a python generator instead of a list).The following python code snippet illustrate the access to the node named
lento retrieve its byte string representation:1rnode['ex/data_group/len'][0].to_bytes() 2 3# same as: 4rnode.get_first_node_by_path('ex/data_group/len').to_bytes()
A
framework.node.NodeInternalsCriteriathat match the internal attributes of interest of the nodes you want to retrieve and which are reachable from the current node. It is equivalent to callingframework.node.Node.get_reachable_nodes()on the node and providing the parameterinternals_criteriawith your criteria object. A list will always be returned, either empty or containing the nodes of interest.A
framework.node.NodeSemanticsCriteriathat match the internal attributes of interest of the nodes you want to retrieve and which are reachable from the current node. It is equivalent to callingframework.node.Node.get_reachable_nodes()on the node and providing the parametersemantics_criteriawith the criteria object. A list will always be returned, either empty or containing the nodes of interest.
See also
To learn how to create criteria objects refer to Search for Nodes in a Graph.
As a value, you can provide:
A
framework.node.Node: In this case the methodframework.node.Node.set_contents()will be called on the node with the node as parameter.A
framework.node.NodeSemantics: In this case the methodframework.node.Node.set_semantics()will be called on the node with the semantics as parameter.A python integer: In this case the method
framework.value_types.INT.set_raw_values()of the INT object embedded in the targeted node will be called with the integer as parameter. (Have to be only used with typed-value nodes embedding anINT.)A byte string: In this case the method
framework.node.Node.absorb()will be called on the node with the byte string as parameter.
Warning
These methods should generally be called on a frozen graph.
4.4. Change a Node¶
You can change the content of a specific node by absorbing a new content (refer to Byte String Absorption).
You can also temporarily change the node value of a terminal node (until the next time
framework.node.Node.unfreeze() is called on it) with the method
framework.node.Node.set_frozen_value() (refer to Generate Data a.k.a. Freeze a Graph).
But if you want to make some more disruptive change and change a terminal node to a non-terminal node for instance, you have two options. Either you do it from scratch and you leverage the function described in the section Create Nodes with Low-Level Primitives. For instance:
1node_to_change.set_values(value_type=String(max_sz=10))
Or you can do it by replacing the content of one node with another one. That allows you for
instance to add a data from a model to another model. To illustrate this possibility
let’s consider the following code that change the node data0 of our data
model example with an USB STRING descriptor (yes, that does not make sense, but you can do
it if you like ;).
1 from framework.plumbing import *
2
3 fmk = FmkPlumbing()
4 fmk.run_project(name='tuto')
5
6 usb_str = fmk.dm.get_external_atom(dm_name='usb', data_id='STR')
7
8 ex_node = fmk.dm.get_atom('ex')
9
10 ex_node['ex/data0'] = usb_str # Perform the substitution
11
12 ex_node.show() # Data.show() will call .show() on the embedded node
The result is shown below:
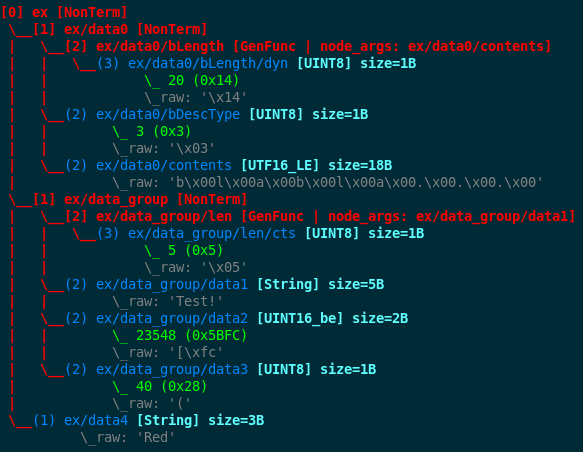
Note
Releasing constraints (like a CRC, an offset, a length, …) of an altered
data can be useful if you want fuddly to automatically recomputes the constraint for you and
still comply to the model. Refer to Generate Data a.k.a. Freeze a Graph.
You can also add subnodes to non-terminal nodes through the usage of framework.node.NodeInternals_NonTerm.add().
For instance the following code snippet will add a new node after the node data2.
1data2_node = ex_node['ex/data_group/data2'][0]
2ex_node['ex/data_group$'][0].add(Node('my_node', values=['New node added']),
3 after=data2_node)
Thus, if ex_node before the modification is:
[0] ex [NonTerm]
\__(1) ex/data0 [String] size=4B
| \_ codec=iso8859-1
| \_raw: b'Plip'
\__[1] ex/data_group [NonTerm]
| \__[2] ex/data_group/len [GenFunc | node_args: ex/data_group/data1]
| | \__(3) ex/data_group/len/cts [UINT8] size=1B
| | \_ 5 (0x5)
| | \_raw: b'\x05'
| \__(2) ex/data_group/data1 [String] size=5B
| | \_ codec=iso8859-1
| | \_raw: b'Test!'
| \__(2) ex/data_group/data2 [UINT16_be] size=2B
| | \_ 10 (0xA)
| | \_raw: b'\x00\n'
| \__(2) ex/data_group/data3 [UINT8] size=1B
| \_ 30 (0x1E)
| \_raw: b'\x1e'
\__(1) ex/data4 [String] size=3B
\_ codec=iso8859-1
\_raw: b'Red'
After the modification it will be:
[0] ex [NonTerm]
\__(1) ex/data0 [String] size=4B
| \_ codec=iso8859-1
| \_raw: b'Plip'
\__[1] ex/data_group [NonTerm]
| \__[2] ex/data_group/len [GenFunc | node_args: ex/data_group/data1]
| | \__(3) ex/data_group/len/cts [UINT8] size=1B
| | \_ 5 (0x5)
| | \_raw: b'\x05'
| \__(2) ex/data_group/data1 [String] size=5B
| | \_ codec=iso8859-1
| | \_raw: b'Test!'
| \__(2) ex/data_group/data2 [UINT16_be] size=2B
| | \_ 10 (0xA)
| | \_raw: b'\x00\n'
| \__(2) ex/data_group/my_node [String] size=14B
| | \_ codec=iso8859-1
| | \_raw: b'New node added'
| \__(2) ex/data_group/data3 [UINT8] size=1B
| \_ 30 (0x1E)
| \_raw: b'\x1e'
\__(1) ex/data4 [String] size=3B
\_ codec=iso8859-1
\_raw: b'Red'
4.4.1. Operations on Node Properties and Attributes¶
The following methods enable you to retrieve the kind of content of the node. The provided answer is
for the current configuration (refer to Node Configurations) if the conf parameter is not
provided:
Checking if a node is frozen (refer to Generate Data a.k.a. Freeze a Graph) can be done thanks to the method:
The following methods enable you to change specific node properties or attributes:
Methods related to the keyword
fuzz_weightdescribed in the section Data Model Keywords:Methods related to the keywords
determinist,random,finiteandinfinitedescribed in the section Data Model Keywords:Methods to deal with node attributes and related to the keywords
set_attrsandclear_attrsdescribed in the section Data Model Keywords:
You can test the compliance of a node with syntactic and/or semantic criteria with the method
framework.node.Node.compliant_with(). Refer to the section Search for Nodes in a Graph to
learn how to specify criteria.
Any object can be added to a node as a private attribute. The private object should support the
__copy__ interface. To set and retrieve a private object the following methods are provided:
Node semantics can be defined to view the data model in a specific way, which boils down to be able to search for nodes based on semantic criteria (refer to Search for Nodes in a Graph). To set semantics on nodes or to retrieve them the following methods have to be used:
framework.node.Node.set_semantics(): Take a list of strings (that capture the semantic) or aframework.node.NodeSemanticsframework.node.Node.get_semantics(): Returns aframework.node.NodeSemantics
4.4.2. Node Configurations¶
Alternative node content can be added dynamically to any node of a graph. This is called a node configuration and everything that characterize a node—its type: non-terminal, terminal, generator; its attributes; its links with other nodes; and so on—are included within. A node is then a receptacle for an arbitrary number of configurations.
Note
When a node is created it gets a default configuration named MAIN.
Configuration management is based on the following methods:
framework.node.Node.add_conf(): To add a new configuration.framework.node.Node.remove_conf(): To remove a configuration based on its name.framework.node.Node.is_conf_existing(): To check a configuration existence based on its name.framework.node.Node.set_current_conf(): To change the current configuration of a node with the one whose the name is provided as a parameter.framework.node.Node.get_current_conf(): To retrieve the name of the current node configuration.framework.node.Node.gather_alt_confs(): to gather all configuration names defined in the subgraph where the root is the node on which the method is called.
In what follows, we illustrate some node configuration change based on our data model example
1 rnode.freeze() # We consider there is at least 2 'data2' nodes
2
3 # We change the configuration of the second 'data2' node
4 rnode['ex/data_group/data2:2'][0].set_current_conf('alt1', ignore_entanglement=True)
5 rnode['ex/data_group/data2:2'][0].unfreeze()
6
7 rnode.show()
8
9 # We change back 'data2:2' to the default configuration
10 rnode['ex/data_group/data2:2'][0].set_current_conf('MAIN', ignore_entanglement=True)
11 # We change the configuration of the first 'data2' node
12 rnode['ex/data_group/data2'][0].set_current_conf('alt1', ignore_entanglement=True)
13 # This time we unfreeze directly the parent node
14 rnode['ex/data_group$'][0].unfreeze(dont_change_state=True)
15
16 rnode.show()
See also
Refer to Entangled Nodes about the parameter ignore_entanglement.
If you want to act on a specific configuration of a node without changing first its configuration,
you can leverage the conf parameter of the methods that support it. For instance, all the
methods used for setting the content of a node (refer to Create Nodes with Low-Level Primitives) are configuration
aware.
Note
If you need to access to the node internals (framework.node.NodeInternals) the
following attributes are provided:
framework.node.Node.cc: to access to the node internals of the current configuration.framework.node.Node.c: dictionary to access to the node internals of any configuration based on their name.
4.4.3. Node Corruption Infrastructure¶
You can also leverage the Node-corruption Infrastructure (based on hooks within the code) for
handling various corruption types easily. This infrastructure is especially used by the
generic disruptor tSTRUCT (refer to Generic Disruptors).
This infrastructure is based on the following primitives:
The typical way to perform a corruption with this infrastructure is illustrated in what follows.
This example performs a corruption that changes from the model the allowed amount for a specific
node (targeted_node) of a graph (referenced by rnode) that can be created during the data
generation from the graph.
1 mini = 8
2 maxi = 10
3 rnode.env.add_node_to_corrupt(targeted_node, corrupt_type=Node.CORRUPT_NODE_QTY,
4 corrupt_op=lambda x, y: (mini, maxi))
5
6 corrupt_rnode = Node(rnode.name, base_node=rnode, ignore_frozen_state=False,
7 new_env=True)
8 rnode.env.remove_node_to_corrupt(targeted_node)
From now on, you have still a clean graph referenced by rnode, and a corrupted one referenced
by corrupt_rnode. You can now instantiate some data from corrupt_rnode that complies to an
altered data model (because we change the grammar that constrains the data generation).
The corruption operations currently defined are:
4.4.4. Byte String Absorption¶
This feature is described in the tutorial. Refer to Absorption of Raw Data that Complies to the Data Model to learn about it. The methods which are involved in this process are:
4.5. Miscellaneous Primitives¶
framework.node.Node.get_path_from(): if it exists, return the first path to this node from the node provided as parameter; otherwise return None.framework.node.Node.get_all_paths_from(): similar as the previous method, except it returns a list of all the possible paths.
4.6. Entangled Nodes¶
Node descriptors that contain the qty attribute may trigger the creation of multiple nodes
based on the same description. These nodes are created in a specific way to make them react as a
group. We call the nodes of such a group: entangled nodes. If you perform a modification on
any one node of the group (by calling a setter on the node for instance), all the other
nodes will be affected the same way.
Some node methods are immune to the entanglement, especially all the getters, others enable you to
temporarily break the entanglement through the parameter ignore_entanglement.