3. Data Modeling¶
3.1. Data Model Keywords¶
This section describe the keywords that you could use within the
frame of the framework.node_builder.NodeBuilder
infrastructure. This infrastructure enables you to describe a data
format in a JSON-like fashion, and will automatically translate this
description to fuddly’s internal data representation.
3.1.1. Generic Description Keywords¶
- name
Within
fuddly’s data model every node has a name that should be unique only within its siblings. But when it comes to use theframework.node_builder.NodeBuilderinfrastructure to describe your data format, if you want to use the same name in a data model description, you have to add an extra key to keep it unique within the description, and thus allowing you to refer to this node anywhere in the description. The following example result in giving the same name to different nodes:'my_name' ('my_name', 'namespace_1') ('my_name', 'namespace_2')
These names serve as node references during data description. Another option is to use the keyword
namespace.Note
The character
/is reserved and shall not be used in a name.- namespace
[For non-terminal nodes only]
Specify a namespace that will be used for the
nameof all the nodes reachable from the node declaring the namespace. It means that the subnodes will be automatically described by a tuple with the namespace value as second item (refer to the description of the keywordname).- from_namespace
If specified, and some node name are used as inputs (refer for instance to keywords
cloneornode_args), the specified namespace will be used to fetch the nodes. It is equivalent to use a tuple expression for referring to the node with thefrom_namespacevalue as second item.Note that referring to a node without specifying the namespace will be interpreted as using the current namespace. By default (even when no namespaces have been declared), one namespace is always defined from the root node, it can be referred to by
NodeBuilder.RootNS.- contents
Every node description has at least a
nameand acontentsattributes (except if you refer to an already existing node, and in this case you have to use only the name attribute with the targeted node reference). The type of the node you describe will directly depends on what you provide in this field:a python
listwill be considered as a non-terminal node;a Value Type (refer to Value Types) will define a terminal node
a python
function(or everything with a__call__method) will be considered as a generator.a
framework.node.Nodewill be used as a baseline for the description. If no additional keyword is provided, the provided node will be used as is. Otherwise, the additional keywords will be used to complement the description. Note that the keywordnameshould not be provided as it will be picked from the provided node.a python
regular expressionwill represent a node that is terminal or non-terminal but only contains terminal ones (refer to How to Describe a Data Format That Contains Complex Strings).
Note that for defining a function node and not a generator node, you have to state the type attribute to
MH.Leaf.- default
Default value for the node. Only compatible with typed nodes (
framework.node.NodeInternals_TypedValue). It is directly linked to thedefaultparameter of each type constructor. Refer to Value Types for more information.- description
Textual description of the node. Note this information is shown by the method
framework.node.Node.show().- qty
Specify the amount of nodes to generate from the description, or a tuple
(min, max)specifying the minimum (which can be 0) and the maximum of node instances you wantfuddlyto generate.Note
-1means infinity. It makes only sense for absorption operation (refer to Absorption of Raw Data that Complies to the Data Model), because for data generation, a strict limit (framework.node.NodeInternals_NonTerm.INFINITY_LIMIT) is set to avoid getting unintended too big data. If you intend to get such kind of data, specify explicitly the maximum, or use a disruptor to do so (Defining Specific Disruptors).- default_qty
Specify the default amount of nodes to generate from the description. It should be within
<min, max>.- clone
Allows to make a full copy of an existing node by providing its reference.
- type
Used only by the
framework.node_builder.NodeBuilderinfrastructure if there is an ambiguity to determine the node type. This attributes accept the following values:MH.Leaf: to specify a terminal node, either a value type or a function.MH.NonTerminal: to specify a non terminal node.MH.Generator: to specify a generator node.
- alt
Allows to specify alternative contents, by providing a list of descriptors like here under:
'alt': [ {'conf': 'config_n1', 'contents': SINT8(values=[1,4,8])}, {'conf': 'config_n2', 'contents': UINT16_be(min=0xeeee, max=0xff56), 'determinist': True} ]
- conf
Used within the scope of the description of an alternative configuration. It set the name of the alternative configuration.
- evolution_func
This attribute allows to provide a function that will be used in the case the described node is instantiated more than once by a containing non-terminal node further to a
framework.node.Node.freeze()operation (refer to theqtykeyword). The function will be called on every node instance (but the first one) before this node incorporate the frozen form of the non-terminal. Besides, the node returned by the function will be used as the base node for the next instantiation (which makes node evolution easier). The function shall have the following signature:func_name( Node ) --> Node
- custo_set, custo_clear
These attributes are used to customize the behavior of the described node.
custo_setis to enable some behavior modes, whereascusto_clearallows to disable them. What is expected is either a single mode or a list of modes. The available modes depend on the kind of node.For non-terminal node, the customizable behavior modes are:
MH.Custo.NTerm.MutableClone: By default, this mode is enabled. When enabled, it means that for child nodes which can be instantiated many times (refer toqtyattribute), all instances will be set as mutable. If it is disabled, when a child node is instantiated more than once, only the first instance is set mutable, the others have this attribute cleared to prevent generic disruptors from altering them. This mode aims at limiting the number of test cases, by pruning what is assumed to be redundant.MH.Custo.NTerm.CycleClone: By default, this mode is disabled. When enabled, and when the subnodes need to be duplicated because of aqtygreater than 1, the non-terminal node will walk through each copy, in order to cycle among the various shapes/values of the subnodes. Note this customization won’t be effective if an evolution function is provided through the keywordevolution_func.MH.Custo.NTerm.FrozenCopy: By default, this mode is enabled. When enabled, it means that for child nodes which can be instantiated many times (refer toqtyattribute), the instantiation process will make a frozen copy of the node, meaning that it will be the exact copy of the original one at the time of the copy. If disabled, the instantiation process will ignore the frozen state, and thus will release all the constraints.MH.Custo.NTerm.FullCombinatory: By default, this mode is disabled. When enabled, walking through a non-terminal node will generate all “possible” combination of forms for each subnode. The various considered forms for a subnode are based on theqtyanddefault_qtyparameter provided. Thus there are at most 3 different forms that boil down to the different amounts of subnodes (max, min and default values), and at least 1 if all are the same. Other possible values in the range<min, max>are reachable inrandommode, or by changing the subnode quantity manually. When this mode is disabled, walking through the non-terminal node won’t generate all possible combinations but a subset of it based on a simpler algorithm that will walk through each subnode and iterate for their different forms without considering the previous subnodes forms.Note
Note that if the node is not frozen at the time of the copy, this customization won’t have any effect. The main interest is in conjunction with the disruptors (like
tTYPE,tWALK, …) which are based on theModelWalkerinfrastructure (refer to The Model Walker Infrastructure). Indeed, this infrastructure releases constraints on non-terminal nodes before providing a new model instance. Releasing constraints triggers child nodes reconstruction for each non-terminal. And as the terminal children will be frozen at that time, the reconstruction will take into account this customization mode.MH.Custo.NTerm.StickToDefault: By default, this mode is disabled. When enabled, walking through a non-terminal node won’t generate all “possible” combination of forms for each subnode. Only the default quantity (refer to keyworddefault_qty) is leveraged. Walking through such nodes will generate new forms only if different shapes have been defined (refer to keywordshape_typeandsection_type).MH.Custo.NTerm.CollapsePadding: By default, this mode is disabled. When enabled, every time two adjacentBitField‘s (within its scope) are found, they will be merged in order to remove any padding in-between. This is done “recursively” until any inner padding is removed.Note
To be compatible with an absorption operation, the non-terminal set with this customization should comply with the following requirements:
The
lsb_paddingparameter shall be set toTrueon every relatedBitField‘s.The
endianparameter shall be set toVT.BigEndianon every relatedBitField‘s.the
qtykeyword should not be used on the children except if it is equal to1, or(1,1).
MH.Custo.NTerm.DelayCollapsing: By default, this mode is disabled. To be used in conjunction withMH.Custo.NTerm.CollapsePaddingwhen the collapse operation should not be performed in the current non-terminal node but in the parent node. Refer to the code snippet below for an example:{'name': 'request', 'custo_set': MH.Custo.NTerm.CollapsePadding, 'contents': [ {'name': 'header', 'contents': BitField(subfield_sizes=[3,1], endian=VT.BigEndian, subfield_val_extremums=[[0,7], [0,1]])}, {'name': 'payload', 'custo_set': [MH.Custo.NTerm.CollapsePadding, MH.Custo.NTerm.DelayCollapsing], 'contents': [ {'name': 'status', 'contents': BitField(subfield_sizes=[1,3], endian=VT.BigEndian, subfield_values=[None,[0,1,2]])}, {'name': 'count', 'contents': UINT16_be()} ]}, # [...] }
Without this mode, when resolving the request node to get the byte-string the payload subnode will be resolved too early and will produce a byte-string without any collapse operation.
For generator node, the customizable behavior modes are:
MH.Custo.Gen.ForwardConfChange: By default, this mode is enabled. If enabled, a call toframework.node.Node.set_current_conf()will be called on the generated node (default behavior).MH.Custo.Gen.CloneExtNodeArgs: By default, this mode is disabled. If enabled, during a cloning operation (e.g., full copy of the modeled data containing this node) if the node parameters do not belong to the graph representing the data, they will be cloned (full copy). Otherwise, they will just be referenced (default behavior). Rationale for default behavior: When a generator or function node is duplicated within a non terminal node, the node parameters may be unknown to it, thus considered as external, while still belonging to the full data.MH.Custo.Gen.ResetOnUnfreeze: By default, this mode is enabled. If enabled, a call toframework.node.Node.unfreeze()on the node will provoke the reset of the generator itself, meaning that the next time its value will be asked for, it will be recomputed (default behaviour). If unset, a call to the methodframework.node.Node.unfreeze()will provoke the call of this method on the already existing generated node (and if it didn’t exist by this time it would have been computed first).MH.Custo.Gen.TriggerLast: By default, this mode is disabled. If enabled, the triggering of a generator is postpone until everything else has been resolved. It is especially useful when you describe a generator that use a node with an existence condition and that this condition cannot be resolved at the time the generator would normally trigger (which is when it is reached while walking through the graph).
For function node, the customizable behaviors mode are:
MH.Custo.Func.FrozenArgs: By default, this mode is enabled. When enabled, the node parameters are frozen before being provided to the function node. If disabled, the node parameters are directly provided to the function node (without being frozen first).MH.Custo.Func.CloneExtNodeArgs: By default, this mode is disabled. Refer to the description of the corresponding generator node mode.
3.1.2. Keywords to Describe Non Terminal Node¶
- shape_type
Allows to choose the order to be enforce by a non-terminal node to its children.
MH.Orderedspecifies that the children should be kept strictly in the order of the description.MH.Randomspecifies there is no order to enforce between any node descriptor (which can expand to several nodes), except if the parent node has thedeterministattribute.MH.FullyRandomspecifies there is no order to enforce between every single nodes.MH.Pickspecifies that only one node among the children should be kept at a time—the choice is randomly performed except if the parent has thedeterministattribute—as per the weight associated to each child node.- weight
Used within the scope of a shape description for a non-terminal node. A non-terminal node can organize all its child nodes in various way by describing different shapes. Each shape has a weight which is used either—when the non-terminal node is random—as a way to determine the chance that
fuddlywe use it during the data generation process, or as a mean to order the shape—when the node is put in determinist mode. Let’s look at the example here under:{'name': 'test', 'contents': [ # SHAPE 1 {'weight': 20, 'contents': [ {'section_type': MH.Random, 'contents': [ {'contents': String(max_sz=10), 'name': 'val1', 'qty': (1, 5)}, ... # SHAPE 2 {'weight': 10, 'contents': [ {'section_type': MH.FullyRandom, 'contents': [ {'name': 'val1'}, ...
Note
A shape description is composed of the two attributes
weightandcontents.- section_type
Similar to
shape_typekeyword. But only valid for describing a section within a non-terminal node, and limited to this section. The following example illustrates that:{'name': 'test', 'shape_type': MH.Random 'contents': [ {'name': 'val1', 'contents': String(values=['OK', 'KO']), 'qty': (0, 5)}, {'section_type': MH.Ordered, 'contents': [ {'name': 'val2', 'contents': UINT16_be(values=[10, 20, 30])}, {'name': 'val3', 'contents': String(min_sz=2, max_sz=10, alphabet='XYZ')}, {'name': 'val4', 'contents': UINT32_le(values=[0xDEAD, 0xBEEF])}, ]} {'name': 'val5', 'contents': String(values=['OPEN', 'CLOSE']), 'qty': 3} ]}
- duplicate_mode
Modify the behavior of the instantiating procedure when a child node is instantiated more than once. This can be set to:
MH.Copy: A new instance corresponds to a full copy operation.MH.ZeroCopy: A new instance corresponds to a new reference of the child node.
- weights
To be used optionally in the frame of a non-terminal node along with a
MH.Picktype. If used this attribute shall contains an integer tuple describing the weight for each one of the subsequent nodes to be picked. Can be used within a section description, or directly in the non-terminal nodes, if it has aMH.Picktype.- separator
When specified, the non-terminal will add a separator between each one of its children. This attribute has to be filled with a separator descriptor such as what is illustrated below:
'separator': {'contents': {'name': 'sep', 'contents': String(values=['\n'])}, 'prefix': False, 'suffix': False, 'unique': True, 'always': False},
The keys
prefix,suffix,uniqueandalwaysare optional. They are described below.See also
Refer to How to Describe the Separators of a Data Format for an example using separators.
- prefix
Used optionally within a separator descriptor. If set to
True, a separator will be placed just before the first child.- suffix
Used optionally within a separator descriptor. If set to
True, a separator will be placed just after the last child.- unique
Used optionally within a separator descriptor. If set to
True, the inserted separators will be independent from each other (full node copy). Otherwise, the separators will be references to a unique node (zero copy).- always
Used optionally within a separator descriptor. If set to
True, the separator will be always generated even if the subnodes it separates are not generated because their evaluated quantity is 0.- encoder
If specified, an encoder instance should be provided. The encoding will be applied transparently when the binary value of the non terminal node will be retrieved (
framework.node.Node.to_bytes()). Additionally, during an absorption (refer to Absorption of Raw Data that Complies to the Data Model), the decoding will also be performed automatically.Several generic encoders are defined within
framework/encoders.py. But if they don’t match your need, you can define your own encoder by inheriting fromframework.encoders.Encoderand implementing its interface.See also
Refer to How to Describe a Data Format With Some Encoded Parts for an example on how to use this keyword.
Note
Depending on your needs, you could also choose to implement a disruptor to perform your encoding (refer to Defining Specific Disruptors).
3.1.3. Keywords to Describe Generator Node¶
- node_args
List of node parameters to be provided to a generator node or a function node.
- other_args
List of parameters (which are not a
framework.node.Node) to be provided to a generator node or a function node.- provide_helpers
(Optional) If set to True, a special object will be provided to the user-defined function (last parameter) of the generator node or the function node. Otherwise, this object won’t be passed (default behavior). This object is an instance of the class
framework.node.DynNode_Helpers, which enable the user-defined function to have some insight on the current structure of the modeled data.- trigger_last
This keyword is a shortcut for the related node customization mode. Refer to
custo_setandcusto_clear.
3.1.4. Keywords to Import External Data Description¶
- import_from
Name of the data model to import a data description from.
- data_id
Name of the data description to import.
3.1.5. Keywords to Describe Node Properties¶
- determinist
Make the node behave in a deterministic way.
- random
Make the node behave in a random way.
- finite
Make the node finite, meaning that it will exhaust at some point (meaning that it has cycled over all its possible values or shapes) When the situation occurs, a notification is posted in the node environment (refer to Data Manipulation)
- infinite
Make the node infinite, meaning that it will always provide values.
- mutable
Make the node mutable. It is a shortcut for the node attribute
MH.Attr.Mutable.- highlight
Make the node highlighted. It is a shortcut for the node attribute
MH.Attr.Highlight.- set_attrs
List of attributes to set on the node. The current generic attributes are:
MH.Attr.Freezable: If set, the node will be freezable (default behavior), which means that once the node has provided a value (through for instanceframework.node.Node.to_bytes()), the methodframework.node.Node.unfreeze()need to be called on it to get new values, otherwise it won’t change. If unset, the node will always be recomputed. Can be useful for function node, if it needs to be recomputed each time a modification has been performed on its associated graph (e.g., CRC function).MH.Attr.Mutable: If set, generic disruptors will consider the node as being mutable, meaning that it can be altered (default behavior). Otherwise, it will be ignored. When a non-terminal node has this attribute, generic disruptors using the ModelWalker algorithm (liketWALKandtTYPE) will stick to its default form (meaning default quantity will be used for each subnodes and if the node has multiple shapes, the higher weighted one will be used. Likewise for Pick sections). Also, the methodframework.node.Node.unfreeze()won’t perform any changes on non-terminal nodes which are not mutable.MH.Attr.Determinist: This attribute can be set directly through the keywordsdeterministorrandom. Refer to them for details. By default, it is set.MH.Attr.Finite: If set, a node will provide a finite number of values and then will notify it has exhausted. Otherwise, exhaustion will never be notified (default behavior).MH.Attr.Abs_Postpone: Used to postpone absorption by the node. Refer to Absorption of Raw Data that Complies to the Data Model for more information on that topic.MH.Attr.Separator: Used to distinguish a separator. Some disruptors can leverage this attribute to perform their alteration.MH.Attr.Highlight: If set, make the framework display the node in color when printed on the console. This attribute is also used by some disruptors to show the location of their modification.
Note
Most of the generic stateful disruptors will recursively set the attributes
MH.Attr.DeterministandMH.Attr.Finiteon the provided data before performing any alteration.Note
Generator node will transfer the generic attributes to the generated node, except for
MH.Attr.Freezable, andMH.Attr.Mutablewhich are used to change the generator behavior. (If such attributes need to be set or cleared on the generated node, it has to be done directly on it and not on its generator.) Specific attributes related to generators won’t be passed to the generated node.See also
The attributes are defined within
framework.node.NodeInternals.- clear_attrs
List of attributes to clear on the node. The current attributes are the same than for the
set_attrskeyword.- absorb_csts
Used to specify some absorption constraints on the node. Refer to Absorption of Raw Data that Complies to the Data Model for more information on that topic.
- absorb_helper
Used to specify an absorption helper function for the node. Refer to Absorption of Raw Data that Complies to the Data Model for more information on that topic.
- semantics
Used to specify semantics to the node, by way of a list of meaningful strings. Nodes can be searched for and selected based on semantics. Refer to Data Manipulation for more information on that topic.
- fuzz_weight
Used by some stateful disruptors to order their test cases. The heavier the weight, the higher the priority of handling the node.
- sync_qty_with
Allow to synchronize the number of node instances to generate or to absorb with the one specified by reference.
- qty_from
Allow to synchronize the number of node instances to generate or to absorb with the value of the one specified by reference. You can also specify an optional base quantity that will be added to the retrieved value. In this case, you shall provide a
list/tuplewith first the node reference then the base quantity.This keyword is the counterpart of the generator template
framework.dmhelpers.generic.QTY. It is preferable to this generator when the node from which the quantity is retrieved is already resolved at retrieval time. In this case generation and absorption operations will be handled transparently.- sync_size_with, sync_enc_size_with
Allow to synchronize the length of the described node (the one where this keyword is used) with the value of the node specified by reference (which should be an
framework.value_types.INT-based typed-node). These keywords are useful for size-variable node types. They are currently supported for typed-nodes which areframework.value_types.String-based with or without an encoding. Non-terminal nodes are not supported (for absorption). The distinction betweensync_size_withandsync_enc_size_withis that the synchronization will be performed:either with respect to the length of the data retrieved from the node in a decoded form. Decoded means that it is agnostic to the codec specified (e.g.,
utf-8,latin-1, …) in theString, and also, forEncoded-String(e.g.,framework.value_types.GZIP, …) , that it is agnostic to anyframework.encoders.EncodertheStringis wrapped with;or with respect to the length of the encoded form of the data.
Generation and absorption deal with these keywords differently, in order to achieve the expected behavior. For generation, the synchronization goes from the described node to the referenced node (meaning that the data is first pulled from the size-variable node, then the referenced node is set with the length of the pulled data). Whereas for the absorption it goes the other way around.
Note also that you can provide an optional base size that will be added to the length before synchronization in the case of generation, and removed from the length in the case of absorption. In this case, you shall provide a
list/tuplewith first the node reference then the base size.These keywords are the counterpart of the generator template
framework.dmhelpers.generic.LEN. They are preferable to this generator (when the size-variable node is not a non-terminal), because generation and absorption operations will be handled transparently thanks to them.- exists_if
Enable to determine the existence of this node based on a given condition.
See also
Refer to How to Describe a Data Format Whose Parts Change Depending on Some Fields for how to use existence conditions.
- exists_if/and, exists_if/or
Extend the
exists_ifkeyword by allowing to specify a list or a tuple of conditions. The operatorand(respectivelyor) will be used to generate the desired behaviour.{'name': 'test', 'contents': [ {'name': 'opcode', 'contents': String(values=['A3', 'A2'])}, {'name': 'subopcode', 'contents': BitField(subfield_sizes=[15,2,4], subfield_values=[[500], [1,2], [5,6,12]])}, {'name': 'and_condition', 'exists_if/and': [(RawCondition('A2'), 'opcode'), (BitFieldCondition(sf=2, val=[5]), 'subopcode')], 'contents': String(values=['and_condition_true'])} ]}
- exists_if_not
Enable to determine the existence of this node based on the non-existence of another one.
- post_freeze
To be filled with a function. If specified, the function will be called just after the node has been frozen. It takes the node internals as argument (
framework.node.NodeInternals).- specific_fuzzy_vals
Usable for typed-nodes only. This keyword allows to specify a list of additional values to be leveraged by the disruptor
tTYPE(tTYPE - Advanced Alteration of Terminal Typed Node) while dealing with the related node. These additional values are added to the test cases planned by the disruptor (if not already planned).- charset
Used in the context of a regular expression
contents. It enables to specify the charset that will be considered for interpreting the regular expression and for creating the related nodes. Accepted attributes are:MH.Charset.ASCIIMH.Charset.ASCII_EXT(default)MH.Charset.UNICODE
3.1.6. Keywords to Describe Constraints¶
- constraints
List of node constraints specified through
framework.constraint_helpers.Constraintobjects. They will be added to a CSP (Constraint Satisfiability Problem) associated to the currently described data, and resolved whenNode.freeze()is called with the parameterresolve_cspset to True (this is performed by default by the operatortWALK). It should always be associated to a non-terminal node. Refer to How to Describe Constraints of Data Formats for details on how to leverage such feature.Specific operators have been defined to handle CSP:
tWALKcspthat walk through the solutions of the CSP.tCONSTthat negates the constraint one-by-one and output 1 or more samples for each negate constraint.
- constraints_highlight
If set to
True, the value of the nodes implied in a CSP (that could be specified through the keywordconstraint) are highlighted in the console, given the Logger parameterhighlight_marked_nodesis set to True.
3.2. Value Types¶
The current types usable within a terminal node are listed in this
section. Each category (Integer, String, BitField)
supports different parameters that allows to more accurately specify a
data model, which enables fuddly to perform more enhanced fuzzing.
Note
These parameters will be especially leveraged by the generic
disruptor tTYPE
(framework.generic_data_makers.d_fuzz_typed_nodes). Refer to
Generic Disruptors for more information on it, and to
Defining Specific Disruptors, for how to create your own disruptors.
3.2.1. Integer¶
All integer types listed below provide the same interface
(framework.value_types.INT). Their constructor take the
following parameters:
values[optional, default value: None]List of the integers that are considered valid for the node backed by this Integer object. The default value is the first element of the list.
min[optional, default value: None]Minimum valid value for the node backed by this Integer object.
max[optional, default value: None]Maximum valid value for the node backed by this Integer object.
default[optional, default value: None]If not None, this value will be provided by default at first when
framework.value_types.INT.get_value()is called.determinist[default value: True]If set to
Truegenerated values will be in a deterministic order, otherwise in a random order.This parameter is for internal usage and will always follow the hosting node instructions. If you want to change the deterministic order you have to do it at the node level by using the data model keyword
determinist(refer to Keywords to Describe Node Properties).values_desc[optional, default value: None]Dictionary that maps integer values to their descriptions (character strings). Leveraged for display purpose. Even if provided, all values do not need to be described.
All these parameters are optional. If you don’t specify all of them the constructor will let more freedom within the data model. But if you have accurate information, don’t hesitate to add them in the data model, as it does not weaken the test cases that will be generated by the generic disruptors, quite the opposite.
Below the different currently defined integer types, and the corresponding outputs for a data generated from them:
framework.value_types.UINT8: unsigned integer on 8 bitframework.value_types.SINT8: signed integer on 8 bit (2’s complement)framework.value_types.UINT16_be: unsigned integer on 16 bit, big endianframework.value_types.UINT16_le: unsigned integer on 16 bit, little endianframework.value_types.SINT16_be: signed integer on 16 bit (2’s complement), big endianframework.value_types.SINT16_le: signed integer on 16 bit (2’s complement), little endianframework.value_types.UINT32_be: unsigned integer on 32 bit, big endianframework.value_types.UINT32_le: unsigned integer on 32 bit, little endianframework.value_types.SINT32_be: signed integer on 32 bit (2’s complement), big endianframework.value_types.SINT32_le: signed integer on 32 bit (2’s complement), little endianframework.value_types.UINT64_be: unsigned integer on 64 bit, big endianframework.value_types.UINT64_le: unsigned integer on 64 bit, little endianframework.value_types.SINT64_be: signed integer on 64 bit (2’s complement), big endianframework.value_types.SINT64_le: signed integer on 64 bit (2’s complement), little endianframework.value_types.INT_str: ASCII encoded integer
For framework.value_types.INT_str, additional parameters are available:
base[optional, default value: 10]Numerical base that have to be used to represent the integer into a string
letter_case[optional, default value: ‘upper’]Only for hexadecimal base. It could be
'upper'or'lower'for representing hexadecimal numbers with these respective letter cases.min_size[optional, default value: None]If specified, the integer representation will have a minimum size (with added zeros when necessary).
reverse[optional, default value: False]Reverse the order of the string if set to
True.
3.2.2. String¶
All string types listed below provide the same interface
(framework.value_types.String). Their constructor take the
following parameters:
values[optional, default value: None]List of the character strings that are considered valid for the node backed by this String object. The default string is the first element of the list.
size[optional, default value: None]Valid character string size for the node backed by this String object.
min_sz[optional, default value: None]Minimum valid size for the character strings for the node backed by this String object. If not set, this parameter will be automatically inferred by looking at the parameter
valueswhether this latter is provided.max_sz[optional, default value: None]Maximum valid size for the character strings for the node backed by this String object. If not set, this parameter will be automatically inferred by looking at the parameter
valueswhether this latter is provided.deteterminist[default value: True]If set to
Truegenerated values will be in a deterministic order, otherwise in a random order.This parameter is for internal usage and will always follow the hosting node instructions. If you want to change the deterministic order you have to do it at the node level by using the data model keyword
determinist(refer to Keywords to Describe Node Properties).codec[default value: ‘latin-1’]Codec to use for encoding the string (e.g., ‘latin-1’, ‘utf8’). Note that depending on the charset, additional fuzzing cases are defined.
case_sensitive[default value: True]If the string is set to be case sensitive then specific additional test cases will be generated in fuzzing mode.
default[optional, default value: None]If not None, this value will be provided by default at first when
framework.value_types.String.get_value()is called.extra_fuzzy_list[optional, default value: None]During data generation, if this parameter is specified with some specific values, they will be part of the test cases generated by the generic disruptor tTYPE.
absorb_regexp[optional, default value: None]You can specify a regular expression in this parameter as a supplementary constraint for data absorption operation (refer to Absorption of Raw Data that Complies to the Data Model for more information on that topic).
alphabet[optional, default value: string.printable]The alphabet to use for generating data, in case no
valuesis provided. Also use during absorption to validate the contents. It is checked if there is novalues.values_desc[optional, default value: None]Dictionary that maps string values to their descriptions (character strings). Leveraged for display purpose. Even if provided, all values do not need to be described.
max_encoded_sz[optional, default value: None]Only relevant for subclasses that leverage the encoding infrastructure. Enable to provide the maximum legitimate size for an encoded string.
encoding_arg[optional, default value: None]Only relevant for subclasses that leverage the encoding infrastructure and that allow their encoding scheme to be configured. This parameter is directly provided to
framework.value_types.String.init_encoding_scheme().
Some String subclasses leverage the String encoding infrastructure,
that enables to handle transparently any encoding scheme:
The input values are the same as for the
Stringtype.Fuzzing test cases are generated based on the raw values, and then are encoded properly.
Some test cases may be defined on the encoding scheme itself.
Note
To define a String subclass handling a specific encoding, you first have to define
an encoder class that inherits from framework.encoders.Encoder (you may also use an
existing one, if it fits your needs).
Then you have to create a subclass of String decorated by framework.value_types.from_encoder()
with your encoder class in parameter.
Additionally, you can overload framework.value_types.String.encoding_test_cases() if you want
to implement specific test cases related to your encoding. They will be automatically added to
the set of test cases to be triggered by the disruptor tTYPE.
Note that the encoder you defined can also be used by a non-terminal node (refer to How to Describe a Data Format With Some Encoded Parts).
Below the different currently defined string types:
framework.value_types.String: General purpose character string.framework.value_types.Filename: Filename. Similar to the typeString, but some disruptors liketTYPEwill generate more specific test cases.framework.value_types.FolderPath: FolderPath. Similar to the typeFilename, but generated test cases are slightly different.framework.value_types.GZIP:Stringcompressed withzlib. The parameterencoding_argis used to specify the level of compression (0-9).framework.value_types.GSM7bitPacking:Stringencoded in conformity withGSM 7-bitspacked format.framework.value_types.Wrapper: to be used as a mean to wrap aStringwith a prefix and/or a suffix, without defining specific nodes for that (meaning you don’t need to model that part and want to simplify your data description).
3.2.3. BitField¶
The type framework.value_types.BitField takes the following
parameters:
subfield_limits[optional, default value: None]List of the limits of each sub-fields (mutually exclusive with
subfield_sizes), expressed in increasing order. For instance a limit list[2, 6]defines the sub-fields0..1(2 bits size) and2..5(4 bits size), for a totalBitFieldsize of 6 bits. Note that the list begin from the least significant sub-field to the more significant sub-field.subfield_sizes[optional, default value: None]List of the size of each sub-fields (mutually exclusive with
subfield_limits), beginning from the least significant sub-field to the more significant sub-field.subfield_values[optional, default value: None]List of valid values for each sub-fields. Look at the following examples for usage. For each sub-field value list, the first value is the default.
subfield_val_extremums[optional, default value: None]List of minimum and maximum value for each sub-fields. Look at the following examples for usage.
padding[default value: 0]Should be either set to
0or1for completion of theBitfieldto a byte boundary if it is not a byte-multiple. Note that the methodframework.value_types.BitField.extend_right()allows to merge twoBitFieldwhich could result in padding deletion.lsb_padding[default value: True]If there is a need for padding, it will be added next to the least significant bit if this parameter is set to
True, otherwise next to the most significant bit. This operation is performed before endianness encoding.endian[default value: VT.LittleEndian]Endianness for encoding the BitField.
determinist[default value: True]If set to
Truegenerated values will be in a deterministic order, otherwise in a random order. Note that in determinist mode, all the values such aBitFieldshould be able to generate are not covered but only a subset of them (i.e., all combinations are not computed). It has been chosen to only keep the value based on the following algorithm: “exhaust each subfield one at a time”. The rationale is that in most cases, computing all combinations does not make sense, especially for fuzzing purpose. Additionally, note that such nominal generation are not the one used by the generic disruptortTYPEwhich rely onBitFieldfuzzy mode (reachable throughframework.value_types.VT_Alt.enable_fuzz_mode()).This parameter is for internal usage and will always follow the hosting node instructions. If you want to change the deterministic order you have to do it at the node level by using the data model keyword
determinist(refer to Keywords to Describe Node Properties).default[optional, default value: None]If not None, it should be the list of default value for each sub-field. They will be provided by default at first when
framework.value_types.BitField.get_value()is called.subfield_descs[optional, default value: None]List of descriptions (character strings) for each sub-field. To describe only part of the sub-fields, put a
Noneitem for the others. This parameter is used for display purpose. Look at the following examples for usage.subfield_value_descs[optional, default value: None]Dictionary providing descriptions (character strings) for values in each sub-field. More precisely, the dictionary maps subfield indexes to other dictionaries whose provides the mapping between values and descriptions. Leveraged for display purpose. Even if provided, all values do not need to be described. Look at the following examples for usage.
Let’s take the following examples to make BitField usage
obvious. On the first one, we specify the sub-fields of the
BitField by their limit, and for each sub-field we give either a
list of valid values, or a tuple expressing the minimum and maximum
values. For the purpose of this example we use it directly, without
going through the definition of a data model (for this topic refer to
Data Modeling and Defining the Imaginary MyDF Data Model):
1 t = BitField(subfield_limits=[2,6,10,12],
2 subfield_values=[[4,2,1], [2,15,16,3], None, [1]],
3 subfield_val_extremums=[None, None, [3,11], None],
4 padding=0, lsb_padding=True, endian=VT.LittleEndian)
5
6 t.pretty_print()
7
8 # output of the previous call:
9 #
10 # (+|3: 01 |2: 0100 |1: 1111 |0: 10 |padding: 0000 |-) 19616
Note that the output is the first generated value from your
description. To get another one you will have to call
framework.value_types.BitField.get_value() on it. Obviously,
this kind of stuff is done automatically for you during a fuzzing
session.
On the second example we specify the sub-fields of the BitField by
their sizes. And the other parameters are described in the same way as
the first example. We additionally specify the parameter
subfield_descs and subfield_value_descs. Look at the output for the differences.
1 t = BitField(subfield_sizes=[4,4,4],
2 subfield_values=[[4,2,1], None, [10,13]],
3 subfield_val_extremums=[None, [14, 15], None],
4 padding=0, lsb_padding=False, endian=VT.BigEndian,
5 subfield_descs=['first', None, 'last'],
6 subfield_value_descs={0:{4:'optionA',2:'optionB'}})
7
8 t.pretty_print()
9
10 # output of the previous call:
11 #
12 # (+|padding: 0000 |2(last): 1101 |1: 1111 |0(first): 0100 [optionA] |-) 2788
See also
Methods are defined to help for modifying a
framework.value_types.BitField. If you want to
deal with BitField in your specific disruptors, take
a look especially at:
3.3. Helpers¶
3.3.1. Generator Node Templates¶
Hereunder are presented the currently available generator-node templates (which are defined
in framework.dmhelpers.generic):
framework.dmhelpers.generic.LEN()Return a generator that returns the length of a node parameter.
framework.dmhelpers.generic.QTY()Return a generator that returns the quantity of child node instances (referenced by name) of the node parameter provided to the generator.
framework.dmhelpers.generic.TIMESTAMP()Return a generator that returns the current time (in a String node).
framework.dmhelpers.generic.CRC()Return a generator that returns the CRC (in the chosen type) of all the node parameters.
framework.dmhelpers.generic.WRAP()Return a generator that returns the result (in the chosen type) of the provided function applied on the concatenation of all the node parameters.
framework.dmhelpers.generic.CYCLE()Return a generator that iterates other the provided value list and returns at each step a node corresponding to the current value.
framework.dmhelpers.generic.OFFSET()Return a generator that computes the offset of a child node within its parent node.
framework.dmhelpers.generic.COPY_VALUE()Return a generator that retrieves the value of another node, and then return a vt node with this value.
framework.dmhelpers.generic.SELECT()Return a generator that select a subnode from a non-terminal node and return it
3.3.2. Block Builders¶
As well as Generator Node Templates, helpers of another kind are defined within the framework to make easier the modeling of some data formats. Basically, it is a bank of block builders that you can use to simplify the process of modeling if they match your needs.
These helpers are provided within framework.dmhelpers. The currently available helper
modules are presented hereunder:
framework.dmhelpers.xmlprovides helpers for modeling XML tags (
framework.dmhelpers.xml.tag_builder()). Note the helpers provide you with a precise data model which enables you to fuzz at XML level as well as at content level or to only focus on the content.For example, the following call:
1 import framework.dmhelpers.xml as xml 2 3 xml_desc = \ 4 xml.tag_builder('C1', params={'p1':'a', 'p2': ['foo', 'bar'], 'p3': 'c'}, 5 struct_mutable=False, tag_name_mutable=True, determinist=False, 6 contents= \ 7 {'name': 'elt-content', 8 'contents': UINT16_be(values=[60,70,80])}, node_name='xml_sample')
will result in the following detailed data model:
1xml_desc = \ 2{'name': 'xml_sample', 3 'separator': {'contents': {'name': ('nl', uuid.uuid1()), 4 'contents': String(values=['\n'], max_sz=100, 5 absorb_regexp='[\r\n|\n]+', codec='latin-1'), 6 'absorb_csts': AbsNoCsts(regexp=True)}, 7 'prefix': False, 'suffix': False, 'unique': False}, 8 'contents': [ 9 {'name': ('start-tag', uuid.uuid1()), 10 'contents': [ 11 {'name': 'prefix', 12 'contents': String(values=['<'], codec='latin-1'), 13 'mutable': False, 'set_attrs': MH.Attr.Separator}, 14 15 {'name': ('content', uuid.uuid1()), 16 'random': True, 17 'separator': {'contents': {'name': ('spc', uuid.uuid1()), 18 'contents': String(values=[' '], max_sz=100, 19 absorb_regexp='\s+', codec='latin-1'), 20 'mutable': False, 21 'absorb_csts': AbsNoCsts(size=True, regexp=True)}, 22 'prefix': False, 'suffix': False, 'unique': False}, 23 'contents': [ 24 25 {'name': ('tag_name', uuid.uuid1()), 26 'contents': String(values=['C1'], codec='latin-1'), 27 'mutable': True}, 28 29 {'section_type': MH.FullyRandom, 30 'contents': [ 31 {'name': ('attr1', uuid.uuid1()), 32 'contents': [ 33 {'name': ('key', 1...), 'contents': String(values=['p1'], codec='latin-1')}, 34 {'name': ('eq', 1...), 'contents': String(values=['='], codec='latin-1'), 35 'set_attrs': MH.Attr.Separator, 'mutable': False}, 36 {'name': ('sep', 1...), 'contents': String(values=['"'], codec='latin-1'), 37 'set_attrs': MH.Attr.Separator, 'mutable': False}, 38 {'name': ('val', 1...), 'contents': String(values=['a'], codec='latin-1')}, 39 {'name': ('sep', 1...)}, 40 ]}, 41 {'name': ('attr2', uuid.uuid1()), 42 'contents': [ 43 {'name': ('key', 2...), 'contents': String(values=['p2'], codec='latin-1')}, 44 {'name': ('eq', 2...), 'contents': String(values=['='], codec='latin-1'), 45 'set_attrs': MH.Attr.Separator, 'mutable': False}, 46 {'name': ('sep', 2...), 'contents': String(values=['"'], codec='latin-1'), 47 'set_attrs': MH.Attr.Separator, 'mutable': False}, 48 {'name': ('val', 2...), 'contents': String(values=['foo', 'bar'], codec='latin-1')}, 49 {'name': ('sep', 2...)}, 50 ]}, 51 {'name': ('attr3', uuid.uuid1()), 52 'contents': [ 53 {'name': ('key', 3...), 'contents': String(values=['p3'], codec='latin-1')}, 54 {'name': ('eq', 3...), 'contents': String(values=['='], codec='latin-1'), 55 'set_attrs': MH.Attr.Separator, 'mutable': False}, 56 {'name': ('sep', 3...), 'contents': String(values=['"'], codec='latin-1'), 57 'set_attrs': MH.Attr.Separator, 'mutable': False}, 58 {'name': ('val', 3...), 'contents': String(values=['c'], codec='latin-1')}, 59 {'name': ('sep', 3...)}, 60 ]} 61 ]} 62 ]}, 63 64 {'name': ('suffix', uuid.uuid1()), 65 'contents': String(values=['>'], codec='latin-1'), 66 'mutable': False, 'set_attrs': MH.Attr.Separator} 67 ]}, 68 69 {'name': 'elt-content', 70 'contents': UINT16_be(values=[60,70,80])}, 71 72 {'name': ('end-tag', uuid.uuid1()), 73 'contents': [ 74 {'name': ('prefix', uuid.uuid1()), 75 'contents': String(values=['</'], codec='latin-1'), 76 'mutable': False, 'set_attrs': MH.Attr.Separator}, 77 {'name': ('content', uuid.uuid1()), 78 'contents': String(values=['C1'], codec='latin-1'), 79 'mutable': True}, 80 {'name': ('suffix', uuid.uuid1()), 81 'contents': String(values=['>'], codec='latin-1'), 82 'mutable': False, 'set_attrs': MH.Attr.Separator}, 83 ]} 84 ]}
3.4. Data Model Patterns¶
3.4.1. How to Describe Different Shapes for Some Parts of Data¶
To describe different forms for a non-terminal node, you can define it in terms of shapes like illustrated by the example below:
1 {'name': 'shape',
2 'separator': {'contents': {'name': 'sep',
3 'contents': String(values=[' [!] '])}},
4 'contents': [
5
6 ### SHAPE 1 ####
7 {'weight': 20,
8 'contents': [
9 {'name': 'prefix1',
10 'contents': String(size=10, alphabet='+')},
11
12 {'name': 'body_top',
13 'contents': [
14
15 {'name': 'body',
16 'separator': {'contents': {'name': 'sep2',
17 'contents': String(values=['::'])}},
18 'shape_type': MH.Random,
19 'contents': [
20 {'contents': String(values=['AAA']),
21 'qty': (0, 4),
22 'name': 'str1'},
23 {'contents': String(values=['42']),
24 'name': 'str2'}
25 ]}
26 ]}
27
28 ]},
29
30 ### SHAPE 2 ###
31 {'weight': 20,
32 'contents': [
33 {'name': 'prefix2',
34 'contents': String(size=10, alphabet='>')},
35
36 {'name': 'body'}
37 ]}
38 ]}
The shapes are ordered by their weight. In deterministic mode (refer to Data Model Keywords) that means a non terminal-node will be sequentially resolved from its heavier shape to its lighter shape. In random mode, the weight are used in a probabilistic way.
The example above also illustrates how to represent an optional part
in the description of a data format (within the first shape of the
example, line 20-22). You only have to set the minimum quantity of a
node to 0 (line 21), and it will be considered as an optional
part.
If you iterate over this data model with tWALK(nt_ony=True) (refer
to Generic Disruptors) you will see the various data forms
understood by fuddly which would be leveraged by most of the
generic stateful disruptors.
# First Form
[!] ++++++++++ [!] ::42:: [!]
# Second Form
[!] ++++++++++ [!] ::AAA::AAA::42:: [!]
# Third Form
[!] >>>>>>>>>> [!] ::AAA::AAA::42:: [!]
As you can see, the first and second forms are from SHAPE 1. The
differences between them comes from the optional part: the first form
does not have the optional part while the second one includes it.
Finally, the third form is from the SHAPE 2.
See also
Refer to The Model Walker Infrastructure for more information on the Model Walker infrastructure which makes really easy the implementation of stateful disruptors leveraging the different forms of a data.
See also
Refer to How to Describe a Data Format Whose Parts Change Depending on Some Fields if you need to change the data format depending on the existence of optional parts.
3.4.2. How to Describe the Separators of a Data Format¶
The example below shows how to define the separators for delimiting lines of an imaginary data model (line 2-7), and for delimiting parameters with space characters (line 12-14).
1 {'name': 'separator_test',
2 'separator': {'contents': {'name': 'sep',
3 'contents': String(values=['\n'], absorb_regexp='[\r\n|\n]+'),
4 'absorb_csts': AbsNoCsts(regexp=True)},
5 'prefix': False,
6 'suffix': False,
7 'unique': True},
8 'contents': [
9 {'section_type': MH.FullyRandom,
10 'contents': [
11 {'name': 'parameters',
12 'separator': {'contents': {'name': ('sep',2),
13 'contents': String(values=[' '], absorb_regexp=' +'),
14 'absorb_csts': AbsNoCsts(regexp=True)}},
15 'qty': 3,
16 'contents': [
17 {'section_type': MH.FullyRandom,
18 'contents': [
19 {'name': 'color',
20 'contents': [
21 {'name': 'id',
22 'contents': String(values=['color='])},
23 {'name': 'val',
24 'contents': String(values=['red', 'black'])}
25 ]},
26 {'name': 'type',
27 'contents': [
28 {'name': ('id', 2),
29 'contents': String(values=['type='])},
30 {'name': ('val', 2),
31 'contents': String(values=['circle', 'cube', 'rectangle'], determinist=False)}
32 ]},
33 ]}]},
34 {'contents': String(values=['AAAA', 'BBBB', 'CCCC'], determinist=False),
35 'qty': (4, 6),
36 'name': 'str'}
37 ]}
38 ]}
From this data model you could get a data like that:
CCCC
BBBB
type=circle color=red
type=rectangle color=red
BBBB
AAAA
CCCC
color=red type=cube
Note
Note this data model can be used to absorb data samples
(refer to Absorption of Raw Data that Complies to the Data Model) that may use more than
one empty line as first-level separator (thanks to the
absorb_regexp parameter in line 3), and more than one
space character as second-level separators (thanks to the
absorb_regexp parameter in line 13).
Note
You can also perform specific separator mutation within a
disruptor (refer to Defining Specific Disruptors), as separator nodes have
the specific attribute
framework.node.NodeInternals.Separator set.
3.4.3. How to Describe a Data Format Whose Parts Change Depending on Some Fields¶
The example below shows how to define a data format based on opcodes
and sub-opcodes which change the form of the data itself. We use for
that purpose the keyword exists_if with some subclasses of
framework.node.NodeCondition and node references.
Note
The keyword exists_if can directly take a node
reference. In such case, the condition is the existence of
this node itself.
1 {'name': 'exist_cond',
2 'shape_type': MH.Ordered,
3 'contents': [
4 {'name': 'opcode',
5 'contents': String(values=['A1', 'A2', 'A3'], determinist=True)},
6
7 {'name': 'command_A1',
8 'contents': String(values=['AAA', 'BBBB', 'CCCCC']),
9 'exists_if': (RawCondition('A1'), 'opcode'),
10 'qty': 3},
11
12 {'name': 'command_A2',
13 'contents': UINT32_be(values=[0xDEAD, 0xBEEF]),
14 'exists_if': (RawCondition('A2'), 'opcode')},
15
16 {'name': 'command_A3',
17 'exists_if': (RawCondition('A3'), 'opcode'),
18 'contents': [
19 {'name': 'A3_subopcode',
20 'contents': BitField(subfield_sizes=[15,2,4], endian=VT.BigEndian,
21 subfield_values=[None, [1,2], [5,6,12]],
22 subfield_val_extremums=[[500, 600], None, None],
23 determinist=False)},
24
25 {'name': 'A3_int',
26 'contents': UINT16_be(values=[10, 20, 30], determinist=False)},
27
28 {'name': 'A3_deco1',
29 'exists_if': (IntCondition(10), 'A3_int'),
30 'contents': String(values=['*1*0*'])},
31
32 {'name': 'A3_deco2',
33 'exists_if': (IntCondition([20, 30]), 'A3_int'),
34 'contents': String(values=['+2+0+3+0+'])}
35 ]},
36
37 {'name': 'A31_payload',
38 'contents': String(values=['$ A31_OK $', '$ A31_KO $'], determinist=False),
39 'exists_if': (BitFieldCondition(sf=2, val=[6,12]), 'A3_subopcode')},
40
41 {'name': 'A32_payload',
42 'contents': String(values=['$ A32_VALID $', '$ A32_INVALID $'], determinist=False),
43 'exists_if': (BitFieldCondition(sf=[0, 1, 2], val=[[500, 501], [1, 2], 5]), 'A3_subopcode')}
44 ]}
Note
Existence condition does not have to be located after the node you want to check, it can also be located before. Fuddly will postpone the condition checking in this case.
Example of data generated by such a data model are presented below (in ASCII art):
[0] exist_cond [NonTerm]
\__(1) exist_cond/opcode [String] size=2B
| \_raw: 'A3'
\__[1] exist_cond/command_A3 [NonTerm]
| \__(2) exist_cond/command_A3/A3_subopcode [BitField] size=3B
| | \_ (+|2: 0110 |1: 01 |0: 000001001001001 |padding: 000 |-) 6558280
| | \_raw: 'd\x12H'
| \__(2) exist_cond/command_A3/A3_int [UINT16_be] size=2B
| | \_ 10 (0xA)
| | \_raw: '\x00\n'
| \__(2) exist_cond/command_A3/A3_deco1 [String] size=5B
| \_raw: '*1*0*'
\__(1) exist_cond/A31_payload [String] size=10B
\_raw: '$ A31_OK $'
[0] exist_cond [NonTerm]
\__(1) exist_cond/opcode [String] size=2B
| \_raw: 'A1'
\__(1) exist_cond/command_A1 [String] size=3B
| \_raw: 'AAA'
\__(1) exist_cond/command_A1:2 [String] size=3B
| \_raw: 'AAA'
\__(1) exist_cond/command_A1:3 [String] size=3B
\_raw: 'AAA'
[0] exist_cond [NonTerm]
\__(1) exist_cond/opcode [String] size=2B
| \_raw: 'A2'
\__(1) exist_cond/command_A2 [UINT32_be] size=4B
\_ 48879 (0xBEEF)
\_raw: '\x00\x00\xbe\xef'
Note
Note this data model can be used for generating data and also (without modification) for absorbing data samples that comply to its grammar (refer to Absorption of Raw Data that Complies to the Data Model)
3.4.4. How to Generate Nodes Dynamically (for length, counter, …)¶
The example below shows how to describe a node that will dynamically generate a node containing the length of another one, a variable character string in our case.
1 {'name': 'len_gen',
2 'contents': [
3 {'name': 'len',
4 'contents': lambda x: Node('cts', value_type= \
5 UINT32_be(values=[len(x.to_bytes())])),
6 'node_args': 'payload'},
7
8 {'name': 'payload',
9 'contents': String(min_sz=10, max_sz=100, determinist=False)},
10 ]}
Note the generator is just a specific kind of node
(framework.node.NodeInternals_GenFunc) that embeds a
function that returns a node (framework.node.Node). In
the previous description, the function is provided through the keyword
contents, and it’s a simple lambda function taking a node as
parameter, on which is called
framework.node.Node.to_bytes() to get its bytes
representation and then the len() function. The result is used for
defining a terminal node of type
framework.value_types.UINT32_be (refer to section Integer).
This use case can be described by using the specific generator
template framework.dmhelpers.generic.LEN() which will basically
return the previous lambda function. The following example makes use
of it.
Note
Generator templates are defined as static methods of
framework.dmhelpers.generic.MH. They make the description
of some generic use cases simpler.
1 {'name': 'len_gen',
2 'contents': [
3 {'name': 'len',
4 'contents': LEN(UINT32_be),
5 'node_args': 'payload'},
6
7 {'name': 'payload',
8 'contents': String(min_sz=10, max_sz=100, determinist=False)},
9 ]}
To conclude on this use case, note that the previous description can
be used for data generation, but it won’t be usable as-is for data
absorption (refer to Absorption of Raw Data that Complies to the Data Model). Indeed, the way
absorption works is by walking through the graph and it will reach the
generator first. This one will freeze the string contents by getting
its bytes representation and will create an UINT32_be node with
only one value, the length of the arbitrarily generated string. This
value will be used for validating the corresponding data part within
the raw data to absorb, as the absorption operation will by default
enforce contents equality. Hence, it will fail. To solve this problem,
the simplest solution is to release some local constraints during
absorption, namely we need to release the Contents constraint for
the len node. More simply, we can release all the absorption
constraints for this node, as shown in the following example:
1 {'name': 'len_gen',
2 'contents': [
3 {'name': 'len',
4 'contents': LEN(UINT32_be),
5 'node_args': 'payload',
6 'absorb_csts': AbsNoCsts() # or more accurately AbsCsts(contents=False)
7 },
8
9 {'name': 'payload',
10 'contents': String(min_sz=10, max_sz=100, determinist=False)},
11 ]}
Another solution can be to define an alternate configuration that will be used only for absorption:
1 {'name': 'len_gen',
2 'contents': [
3 {'name': 'len',
4 'contents': LEN(UINT32_be),
5 'node_args': 'payload',
6 'alt': [
7 {'conf': 'ABS',
8 'contents': UINT32_be(max=100)} ]},
9
10 {'name': 'payload',
11 'contents': String(min_sz=10, max_sz=100, determinist=False)},
12 ]}
This solution is more complex, but can revealed itself to be useful for more complex situation.
See also
Look at the example ZIP archive modification to see how to change the node configuration before absorption. And for more insights on that topic refer to Data Modeling and Defining Specific Disruptors.
Finally, let’s take the following example that illustrates other
generator templates, namely
framework.dmhelpers.generic.QTY(),
framework.dmhelpers.generic.CRC() and
framework.dmhelpers.generic.TIMESTAMP().
1 {'name': 'misc_gen',
2 'contents': [
3 {'name': 'integers',
4 'contents': [
5 {'name': 'int16',
6 'qty': (2, 10),
7 'contents': UINT16_be(values=[16, 1, 6], determinist=False)},
8
9 {'name': 'int32',
10 'qty': (3, 8),
11 'contents': UINT32_be(values=[32, 3, 2], determinist=False)}
12 ]},
13
14 {'name': 'int16_qty',
15 'contents': QTY(node_name='int16', vt=UINT8),
16 'node_args': 'integers'},
17
18 {'name': 'int32_qty',
19 'contents': QTY(node_name='int32', vt=UINT8),
20 'node_args': 'integers'},
21
22 {'name': 'tstamp',
23 'contents': TIMESTAMP("%H%M%S"),
24 'absorb_csts': AbsCsts(contents=False)},
25
26 {'name': 'crc',
27 'contents': CRC(UINT32_be),
28 'node_args': ['tstamp', 'int32_qty'],
29 'absorb_csts': AbsCsts(contents=False)}
30 ]}
Note
Note this data model is compatible for data absorption.
Here under an example of data generated by such a data model (in ASCII art):
[0] misc_gen [NonTerm]
\__[1] misc_gen/integers [NonTerm]
| \__(2) misc_gen/integers/int16 [UINT16_be] size=2B
| | \_ 6 (0x6)
| | \_raw: '\x00\x06'
| \__(2) misc_gen/integers/int16:2 [UINT16_be] size=2B
| | \_ 1 (0x1)
| | \_raw: '\x00\x01'
| \__(2) misc_gen/integers/int16:3 [UINT16_be] size=2B
| | \_ 1 (0x1)
| | \_raw: '\x00\x01'
| \__(2) misc_gen/integers/int16:4 [UINT16_be] size=2B
| | \_ 6 (0x6)
| | \_raw: '\x00\x06'
| \__(2) misc_gen/integers/int16:5 [UINT16_be] size=2B
| | \_ 6 (0x6)
| | \_raw: '\x00\x06'
| \__(2) misc_gen/integers/int16:6 [UINT16_be] size=2B
| | \_ 1 (0x1)
| | \_raw: '\x00\x01'
| \__(2) misc_gen/integers/int16:7 [UINT16_be] size=2B
| | \_ 1 (0x1)
| | \_raw: '\x00\x01'
| \__(2) misc_gen/integers/int32 [UINT32_be] size=4B
| | \_ 2 (0x2)
| | \_raw: '\x00\x00\x00\x02'
| \__(2) misc_gen/integers/int32:2 [UINT32_be] size=4B
| | \_ 3 (0x3)
| | \_raw: '\x00\x00\x00\x03'
| \__(2) misc_gen/integers/int32:3 [UINT32_be] size=4B
| \_ 2 (0x2)
| \_raw: '\x00\x00\x00\x02'
\__[1] misc_gen/int16_qty [GenFunc | node_args: misc_gen/integers]
| \__(2) misc_gen/int16_qty/cts [UINT8] size=1B
| \_ 7 (0x7)
| \_raw: '\x07'
\__[1] misc_gen/int32_qty [GenFunc | node_args: misc_gen/integers]
| \__(2) misc_gen/int32_qty/cts [UINT8] size=1B
| \_ 3 (0x3)
| \_raw: '\x03'
\__[1] misc_gen/tstamp [GenFunc | node_args: None]
| \__(2) misc_gen/tstamp/cts [String] size=6B
| \_raw: '170140'
\__[1] misc_gen/crc [GenFunc | node_args: misc_gen/tstamp, misc_gen/int32_qty]
\__(2) misc_gen/crc/cts [UINT32_be] size=4B
\_ 110906314 (0x69C4BCA)
\_raw: '\x06\x9cK\xca'
Which correspond to the following data:
'\x00\x06\x00\x01\x00\x01\x00\x06\x00\x06\x00\x01\x00\x01\x00\x00\x00\x02\x00\x00\x00\x03\x00\x00\x00\x02\x07\x03170140\x06\x9cK\xca'
See also
You may delay the triggering of a generator, until
everything else has been resolved. It is especially
useful when you describe a generator that use a node with
an existence condition and when this condition cannot be
resolved at the time the generator will normally be
triggered (that is when it is reached during the nominal
graph traversal). To postpone this triggering, you have
to set the generator-specific keyword trigger_last to
True. Refer to Data Model Keywords for more information
on the available keywords.
3.4.5. How to Describe a Data Format With Some Encoded Parts¶
The example below shows how to describe a data format with some parts encoded in different ways.
The non-terminal node named enc (lines 9-19) has the attribute encoder
(refer to Data Model Keywords) which means that it will be encoded following the scheme of the
specified encoder. In this case it is the framework.encoders.GZIP_Enc with a level
of compression of 6. Within this node is also defined a typed node (lines 17-18) named
data1 which is encoded in UTF16 little endian through the parameter codec
of framework.value_types.String.
Note also the parameter after_encoding=False (lines 6 and 14), which is supported by every
relevant generator node templates (refer to Generator Node Templates) and enable them to act either
on the encoded form or the decoded form of their node parameters.
1 {'name': 'enc',
2 'contents': [
3 {'name': 'data0',
4 'contents': String(values=['Plip', 'Plop']) },
5 {'name': 'crc',
6 'contents': CRC(vt=UINT32_be, after_encoding=False),
7 'node_args': ['enc_data', 'data2'],
8 'absorb_csts': AbsFullCsts(contents=False) },
9 {'name': 'enc_data',
10 'encoder': GZIP_Enc(6),
11 'set_attrs': [NodeInternals.Abs_Postpone],
12 'contents': [
13 {'name': 'len',
14 'contents': LEN(vt=UINT8, after_encoding=False),
15 'node_args': 'data1',
16 'absorb_csts': AbsFullCsts(contents=False)},
17 {'name': 'data1',
18 'contents': String(values=['Test!', 'Hello World!'], codec='utf-16-le') },
19 ]},
20 {'name': 'data2',
21 'contents': String(values=['Red', 'Green', 'Blue']) }
22 ]}
This data description will enable you to produce data compliant to the specified encoding schemes in a transparent way. Additionally, any fuzzing operations (Defining Specific Disruptors) you want to perform on any data parts will be done before any encoding takes place.
If you want to perform some fuzzing on the encoding scheme itself you will have first to
describe its format. Then it boils down to run some generic disruptors on them or some of your own.
However, note that some value types that support encoding (refer to Value Types) embed
specific test cases on the encoding scheme (which is the case for utf-16-le-encoded strings
for instance).
Finally, absorption (refer to Absorption of Raw Data that Complies to the Data Model) is also supported when encoding is used within your data description. For instance, the following data will be absorbed by the previous data model:
b'Plop\x8c\xd6/\x06x\x9cc\raHe(f(aPd\x00\x00\x0bv\x01\xc7Blue'
To perform that operation you can write the following python code:
1from framework.plumbing import *
2from framework.node import AbsorbStatus
3
4raw_data = b'Plop\x8c\xd6/\x06x\x9cc\raHe(f(aPd\x00\x00\x0bv\x01\xc7Blue'
5
6fmk = FmkPlumbing()
7fmk.run_project(name="tuto")
8enc_dm = fmk.dm.get_atom('enc')
9
10status, off, size, name = enc_dm.absorb(raw_data, constraints=AbsFullCsts())
11if status == AbsorbStatus.FullyAbsorbed:
12 enc_dm.show()
The following picture displays the result of the previous code (triggered by line 12):
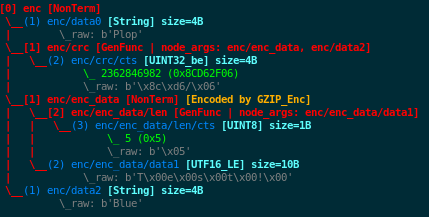
Note
The content absorption constraint is released for the generator nodes crc
(line 8) and len (line 16) in order to allow any value to be absorbed and not limit them to
the value generated the last time the generators triggered (which occurs during node freezing).
Indeed, generators based on these templates will dynamically generate a typed node that contains
only one value—based on the current value their node parameters have while the generator is
triggered.
Note
Line 11 is to make the absorption operation work correctly. Indeed because of the encoding, constraints are not rigid enough to make fuddly work out the absorption without some help.
3.4.6. How to Describe a Data Format That Contains Complex Strings¶
Parts of the data that only contain strings can easily be described using python’s regular expressions. Here are some rules to respect:
Using square brackets
[ ]to indicate a set of characters will result in the creation of aframework.value_types.Stringterminal node that contains an alphabet. Likewise, the usage of.or meta-sequences such as\s,\S,\w,\W,\dor\Dwill lead to the creation of such type of nodes.Anything else will be translated into a
framework.value_types.Stringterminal node that declares a list of values.( )can be used to delimit a portion of the regular expression that need to be translated into a terminal node on its own.
Note
If each item in a list of values are integers an framework.value_types.INT_str will
be created instead of a framework.value_types.String.
(,),[,],?,*,+,{,},|,\,-,.are the only recognised special characters. They cannot be used in an unsuitable context without being escaped (exceptions are made for|,.and-).Are only allowed regular expressions that can be translated into one terminal node or into one non-terminal node composed of terminal ones. If this rule is not respected an
framework.error_handling.InconvertibilityErrorwill be raised.An inconsistency between the charset and the characters that compose the regular expression will result in an
framework.error_handling.CharsetError.
Note
The default charset used by Fuddly is MH.Charset.ASCII_EXT. To change this behaviour,
use the keyword charset (refer to Keywords to Describe Node Properties).
To embody these rules, let’s take some examples:
Example 1: The basics.
1regex = {'name': 'HTTP_version',
2 'contents': '(HTTP)/[0-9]\.(0|1|2|\x33|4|5|6|7|8|9)'}
3# is equivalent to
4classic = {'name': 'HTTP_version',
5 'contents': [
6 {'name': 'HTTP_version_1', 'contents': String(values=["HTTP"])},
7 {'name': 'HTTP_version_2', 'contents': String(values=["/"])},
8 {'name': 'HTTP_version_3',
9 'contents': String(alphabet="0123456789", size=1)},
10 {'name': 'HTTP_version_4', 'contents': String(values=["."])},
11 {'name': 'HTTP_version_5', 'contents': INT_str(min=0, max=9)} ]}
Example 2: Introducing choices. (Refer to Keywords to Describe Non Terminal Node)
1regex = {'name': 'something',
2 'contents': '(333|444)|(foo|bar)|[\d]|[th|is]'}
3# is equivalent to
4classic = {'name': 'something',
5 'shape_type': MH.Pick,
6 'contents': [
7 {'name':'something_1', 'contents':INT_str(values=[333, 444])},
8 {'name':'something_2', 'contents':String(values=["foo", "bar"])},
9 {'name':'something_3', 'contents':String(alphabet="0123456789",size=1)},
10 {'name':'something_4', 'contents':String(alphabet="th|is", size=1)}
11 ]}
Example 3: Using shapes. (Refer to Data Model Patterns)
1regex = {'name': 'something',
2 'contents': 'this[\d](is)|a|digit[!]'}
3# is equivalent to
4classic = {'name': 'something',
5 'contents': [
6 {'weight': 1,
7 'contents': [
8 {'name': 'something_1', 'contents': String(values=['this'])},
9 {'name': 'something_2', 'contents': String(alphabet='0123456789')},
10 {'name': 'something_3', 'contents': String(values=['is'])},
11 ]},
12
13 {'weight': 1,
14 'contents': [
15 {'name': 'something_4', 'contents': String(values=['a'])},
16 ]},
17
18 {'weight': 1,
19 'contents': [
20 {'name': 'something_5', 'contents': String(values=['digit'])},
21 {'name': 'something_6', 'contents': String(alphabet='!')},
22 ]},
23 ]}
Example 4: Using quantifiers and the escape character \.
1regex = {'name': 'something',
2 'contents': '\(this[is]{3,4}the+end\]'}
3# is equivalent to
4classic = {'name': 'something',
5 'contents': [
6 {'name': 'something_1', 'contents': String(values=["(this"])},
7 {'name': 'something_2',
8 'contents': String(alphabet="is", min_sz=3, max_sz=4)},
9 {'name': 'something_3', 'contents': String(values=["th"])},
10 {'name': 'something_4', 'qty': (1, -1),
11 'contents': String(values=["e"])},
12 {'name': 'something_5', 'contents': String(values=["end]"])} ]}
Example 5: Invalid regular expressions.
1error_1 = {'name': 'rejected', 'contents': '(HT(T)P)/'}
2# raise an framework.error_handling.InconvertibilityError
3# because there are two nested parenthesis.
4
5error_2 = {'name': 'rejected', 'contents': '(HT?TP)foo|bar'}
6# raise also an framework.error_handling.InconvertibilityError
7# because a quantifier (that requires the creation of a terminal node)
8# has been found within parenthesis.
3.4.7. How to Describe Constraints of Data Formats¶
When some relations exist between various parts of the data format you want to describe you have
different possibilities within fuddly:
either using some specific keywords that capture basic constraints (e.g.,
qty_from,sync_size_with,exists_if, …);or through Generator nodes (refer to Generator Node Templates);
or by specifying a CSP through the keyword
constraint, which leverage a constraint programming backend (currently limited to thepython-constraintmodule)
The CSP specification case is described in more details in what follows.
To describe constraints in the form of a CSP, you should use the constraints keyword that allows you
to provide a list of framework.constraint_helpers.Constraint objects, which are the
building blocks for specifying constraints between multiple nodes.
For instance, let’s analyse the following data description (extracted from the mydf data model in tuto.py).
1 csp_desc = \
2 {'name': 'csp',
3 'constraints': [Constraint(relation=lambda d1, d2: d1[1]+1 == d2[0] or d1[1]+2 == d2[0],
4 vars=('delim_1', 'delim_2')),
5 Constraint(relation=lambda x, y, z: x == 3*y + z,
6 vars=('x_val', 'y_val', 'z_val'))],
7 'constraints_highlight': True,
8 'contents': [
9 {'name': 'equation',
10 'contents': String(values=['x = 3y + z'])},
11 {'name': 'delim_1', 'contents': String(values=[' [', ' ('])},
12 {'name': 'variables',
13 'separator': {'contents': {'name': 'sep', 'contents': String(values=[', '])},
14 'prefix': False, 'suffix': False},
15 'contents': [
16 {'name': 'x',
17 'contents': [
18 {'name': 'x_symbol',
19 'contents': String(values=['x:', 'X:'])},
20 {'name': 'x_val',
21 'contents': INT_str(min=120, max=130)} ]},
22
23 [...]
You can see that two constraints have been specified (l.3-6) through the specific
framework.constraint_helpers.Constraint objects. The constructor take a mandatory relation parameter
expecting a boolean function that should express a relation between any nodes reachable
from the non-terminal node on which the constraints keyword is attached.
It takes also a vars parameter expecting a list of the names of the nodes
used in the boolean function (in the same order as the parameters of the function).
Note
The constraints keyword can be used several times along the description, but all the specified
framework.constraint_helpers.Constraint will eventually end up in a single CSP.
These constraints, will then be resolved at framework.node.Node.freeze() time (depending if
the parameter resolve_csp is set to True).
Note also that before resolving the CSP it is possible to fix the value of some variables by freezing the related nodes
with the parameter restrict_csp. This is what is performed by the framework.fuzzing_primitives.ModelWalker
infrastructure when walking a specific node which is part of a CSP, so that the walked node won’t be modified
further to the CSP solving process.
Note
The constructor of framework.constraint_helpers.Constraint takes also an optional parameter
var_to_varns in order to support namespaces (used to discriminate nodes having identical
name in the data description). Refer to namespace keyword for more details, and to the csp_ns node
description in the data model mydf (in tuto.py).